三叶运维
三叶运维Redis Cluster
Redis Cluster工作原理
早期Redis 分布式集群部署方案:
- 客户端分区:由客户端程序决定key写分配和写入的redis node,但是需要客户端自己处理写入分配、高可用管理和故障转移等
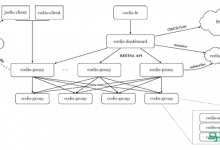
- 代理方案:基于三方软件实现redis proxy,客户端先连接之代理层,由代理层实现key的写入分配,对客户端来说是有比较简单,但是对于集群管节点增减相对比较麻烦,而且代理本身也是单点和性能瓶颈。
在哨兵sentinel机制中,可以解决redis高可用问题,即当master故障后可以自动将slave提升为master,从而可以
保证redis服务的正常使用,但是无法解决redis单机写入的瓶颈问题,即单机redis写入性能受限于单机的内存大
小、并发数量、网卡速率等因素。
因此redis 3.0版本之后推出了无中心架构的redis cluster机制,在无中心的redis集群当中,其每个节点保存当前节点数据和整个集群状态,每个节点都和其他所有节点连接
Redis Cluster特点如下:
- 所有Redis节点使用(PING机制)互联
- 集群中某个节点的是否失效,是由整个集群中超过半数的节点监测都失效,才能算真正的失效
- 客户端不需要proxy即可直接连接redis,应用程序需要写全部的redis服务器IP
- redis cluster把所有的redis node 平均映射到 0-16383个槽位(slot)上,读写需要到指定的redis node上进行
操作,因此有多少个redis node相当于redis 并发扩展了多少倍,每个redis node 承担16384/N个槽位 - Redis cluster预先分配16384个(slot)槽位,当需要在redis集群中写入一个key -value的时候,会使用
CRC16(key) mod 16384之后的值,决定将key写入值哪一个槽位从而决定写入哪一个Redis节点上,从而有效解决单机瓶颈。
Redis cluster架构
Redis cluster基本架构
假如三个主节点分别是:A, B, C 三个节点,采用哈希槽 (hash slot)的方式来分配16384个slot 的话
它们三个节点分别承担的slot 区间是:
节点A覆盖 0-5460 节点B覆盖 5461-10922 节点C覆盖 10923-16383
| 1 2 3 | 节点 A覆盖 0- 5460 节点 B覆盖 5461- 10922 节点 C覆盖 10923- 16383 |

Redis cluster主从架构
Redis cluster的架构虽然解决了并发的问题,但是又引入了一个新的问题,每个Redis master的高可用如何解决?

Redis Cluster 部署架构说明
环境A:3台服务器,每台服务器启动6379和6380两个redis 服务实例,适用于测试环境
10.0.0.7:6379/6380 10.0.0.17:6379/6380 10.0.0.27:6379/6380 另外预留一台服务器做集群添加节点测试。 10.0.0.37:6379/6380
| 1 2 3 4 5 | 10.0.0.7 : 6379 / 6380 10.0.0.17 : 6379 / 6380 10.0.0.27 : 6379 / 6380 另外预留一台服务器做集群添加节点测试。 10.0.0.37 : 6379 / 6380 |
环境B:6台服务器,分别是三组master/slave,适用于生产环境
172.18.200.101 172.18.200.102 172.18.200.103 172.18.200.104 172.18.200.105 172.18.200.106 预留服务器扩展使用 172.18.200.107 172.18.200.108
| 1 2 3 4 5 6 7 8 9 | 172.18.200.101 172.18.200.102 172.18.200.103 172.18.200.104 172.18.200.105 172.18.200.106 预留服务器扩展使用 172.18.200.107 172.18.200.108 |
说明:Redis 5.X和之前版的命令发生了变化,以下分别介绍两个版本5.X和4.X的配置